MongoDB Atlas 是一個雲端平台,允許開發人員和企業在多個雲端服務提供商(如 AWS、Google Cloud、Azure)上部署、管理和擴展 MongoDB 資料庫。它提供自動化的運維功能,如備份、監控、擴展和修補,從而減少了手動操作的需求。
全托管服務:
跨雲支援:
自動擴展:
備份和還原:
安全性:
監控和告警:
全文檢索和向量搜尋:
全球部署和多區域複製:
雲端應用程式:
大數據和分析:
物聯網(IoT):
內容管理系統(CMS):
介紹了這麼多,那我要如何用python去跟他串接呢?
答案是可以透過pymongo,但這邊因為我們要實作日後的RAG,所以主要會使用LangChain此框架
去跟MongoDB Atlas做串接,現在就讓我來介紹一下如何串接吧!
辦一個Atlas 帳號,並創建一個project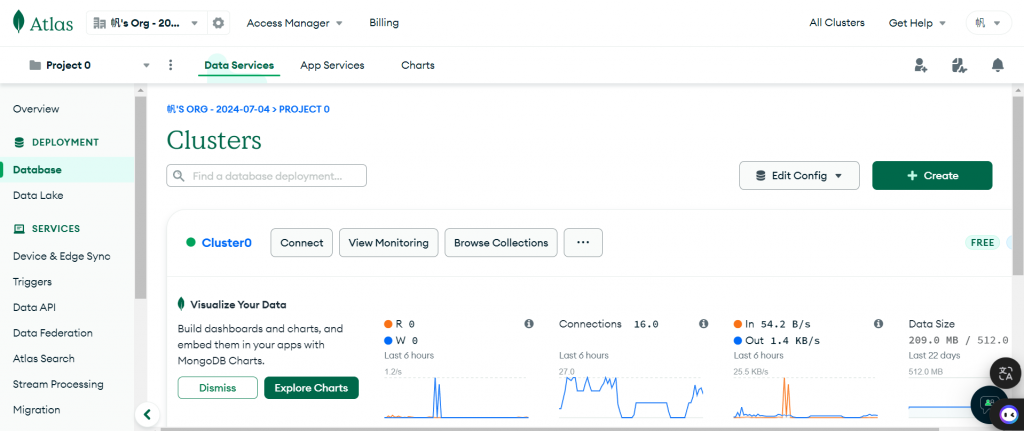
設定好相關資訊後,點擊connect,即可取得endpoint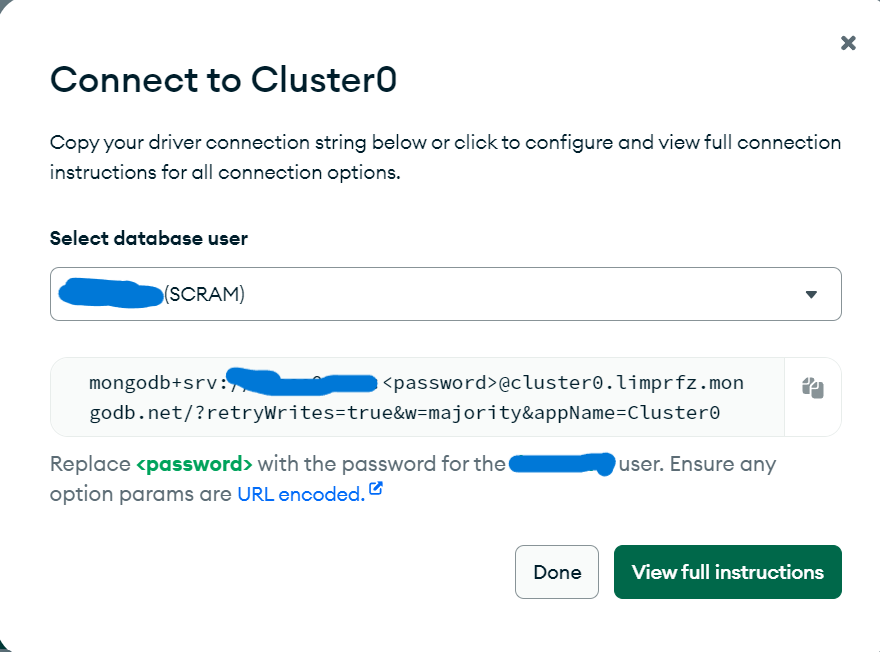
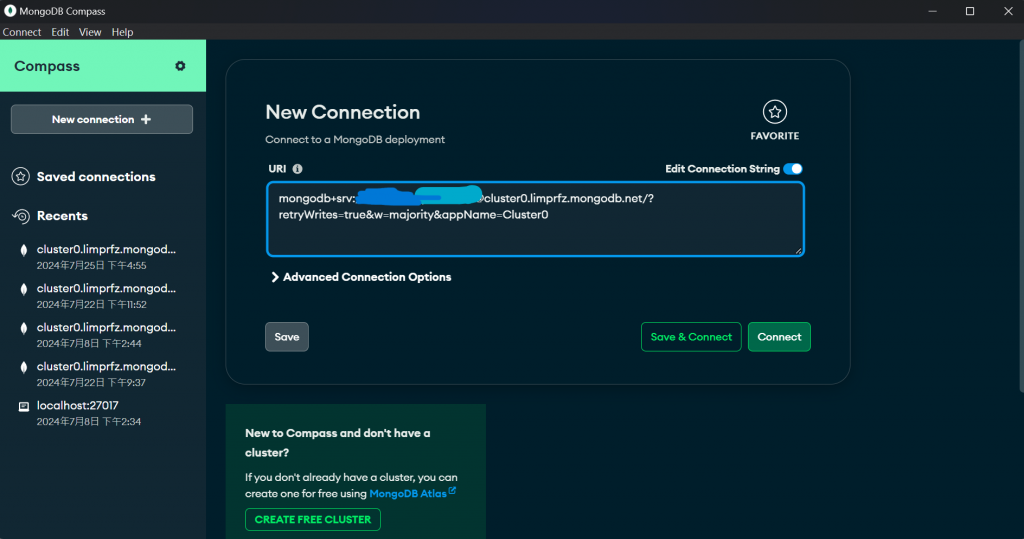
記得在中填入你的密碼
from pymongo import MongoClient # MongoClient 類是用來連接 MongoDB 資料庫的核心工具,可以與 MongoDB 進行交互,如連接到資料庫、查詢和插入數據等
mongo_client = MongoClient("mongodb+srv://xxx:xxxxxx@cluster0.limprfz.mongodb.net/?retryWrites=true&w=majority&appName=Cluster0")
collection = mongo_client["mydatabase"]["mycollection"] # 從 mongo_client 中選擇指定的資料庫和集合,此集合將用存儲和查詢數據
from langchain_community.document_loaders import PyPDFLoader # 載入PDF檔,並以頁為單位進行分割
from rich import print as pprint
loader = PyPDFLoader(file_path='https://ppt.cc/f9nc5x',extract_images=False) # 若PDF中含有圖片,則設為True
docs = loader.load()
# 切割檔案
text_splitter = RecursiveCharacterTextSplitter(separators=[' \n'],chunk_size=10,chunk_overlap=2)
chunks = text_splitter.split_documents(docs)
pprint(chunks[3:6])

# 計算嵌入並插入文件到 MongoDB
for chunk in chunks[3:5]:
embedding = embedding_model.embed_documents([chunk.page_content])[0] # 調用embedding_model 的 embed_documents 方法,對 chunk 中的 page_content (包含文本內容的字符串) 進行嵌入計算
document_data = { # 創建一個新的字典, 目的:準備一個可以插入 MongoDB 的文檔格式
"text": chunk.page_content,
"embedding": embedding,
"source": chunk.metadata['source'],
'page':chunk.metadata['page']
}
collection.insert_one(document_data) # 這行代碼將 document_data 插入到 MongoDB 的集合中(將處理過的 chunk(包含嵌入向量)存儲到 MongoDB 中)
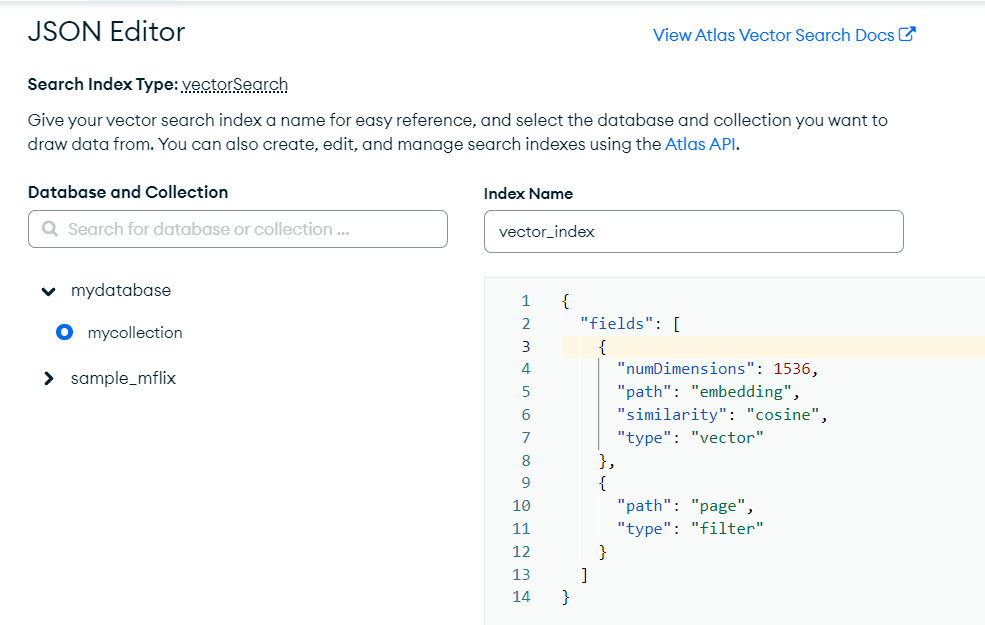
必須先來到官網建立好search規則
選擇要的search方式
(這邊用vector search為例,所以選擇Json Editor)
選擇要得Database和collection,讓search規則適用於此
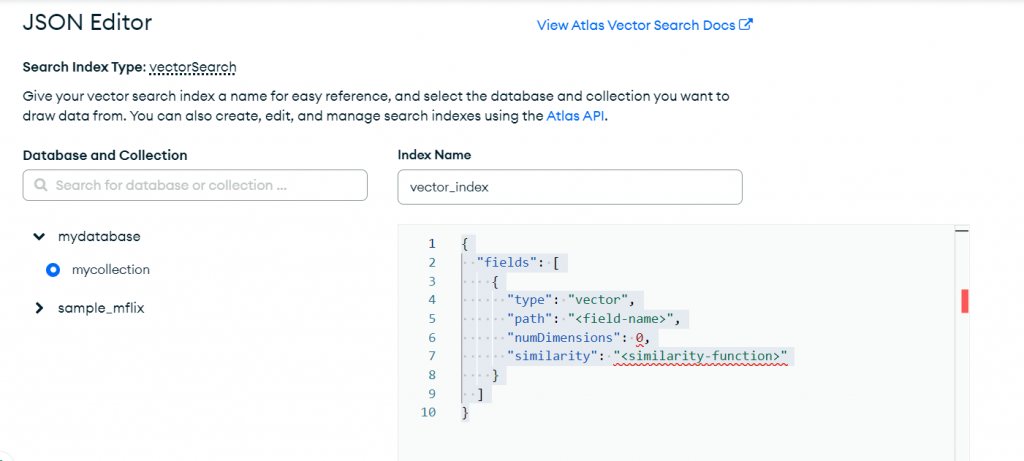
設定好規則後
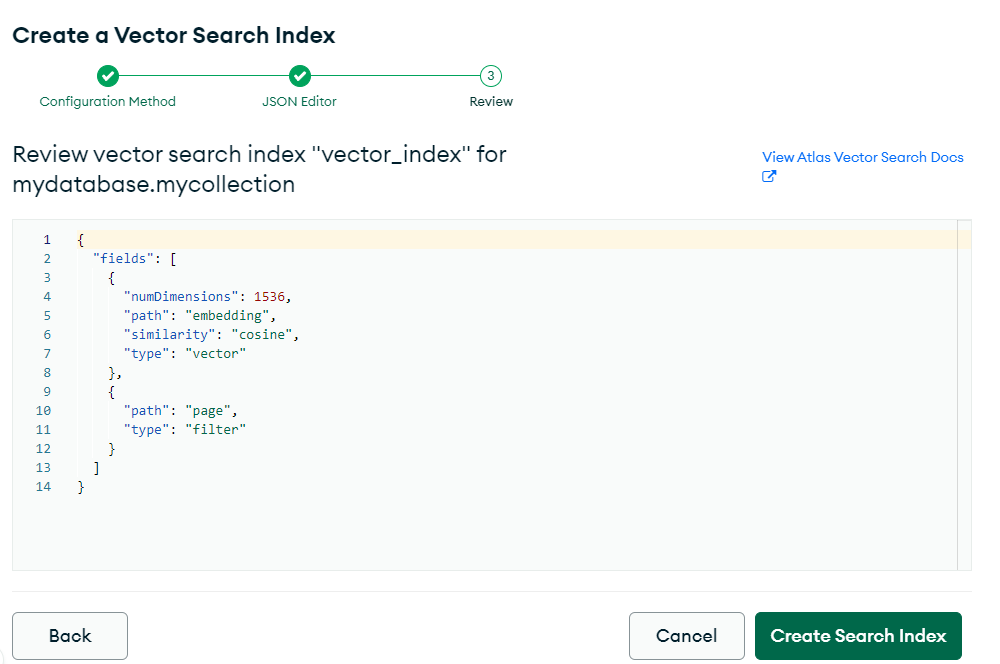
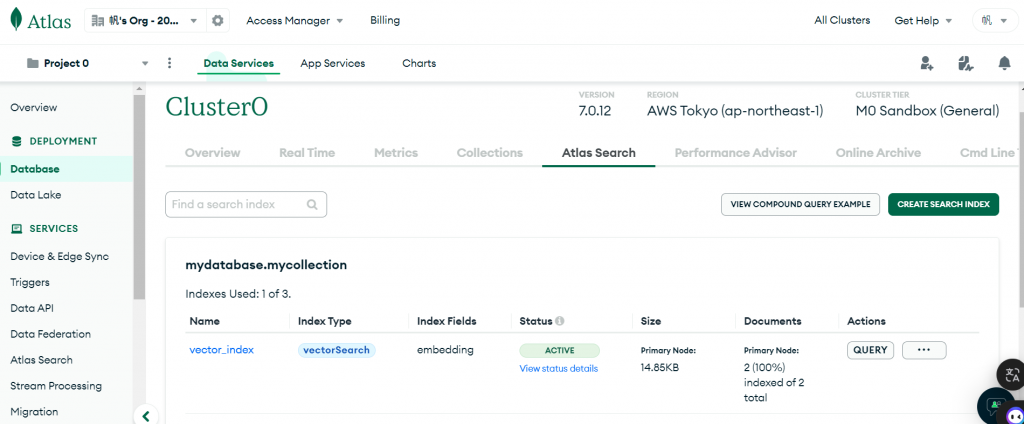
可利用一個範例來檢查模型維度
from langchain_community.vectorstores import MongoDBAtlasVectorSearch # 允許使用嵌入向量來實現 MongoDB Atlas 上的相似性搜索
vectorstore = MongoDBAtlasVectorSearch( # 初始化 MongoDBAtlasVectorSearch 實例,以便進行向量搜索操作
collection=collection, # 指定用於存儲和檢索文檔的 MongoDB 集合對象。已經連接到 MongoDB Atlas 資料庫
embedding=embedding_model, # 指定用於生成嵌入向量的嵌入模型對象,用於將文本轉換成向量表示
index_name="vector_index", # 指定search index的名稱。這個索引用於加速向量搜索操作 (要先在Atlas search額外定義好)
relevance_score_fn="cosine", # 指定用於計算相似度的函數。這裡使用的是餘弦相似度(cosine similarity)來衡量向量之間的相似性
)
pprint(vectorstore.search(query='路口安全',search_type='similarity',kwargs=2))
以上就是MongoDB Atlas介紹,接下來就要開始進入RAG的部分囉!